다중 차량 배송경로 탐색 알고리즘
다중 차량 배송경로 탐색 알고리즘
여러대 차량의 배송경로를 동시에 연산하는 휴리스틱 알고리즘을 개발.
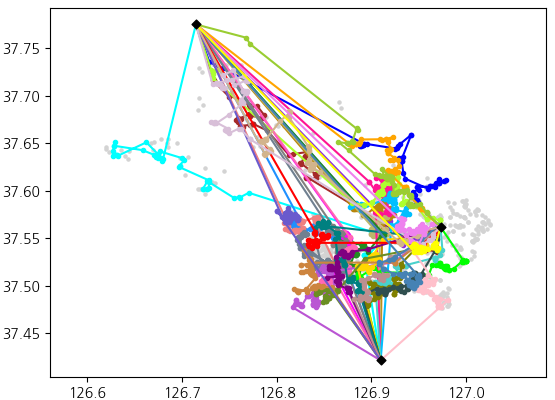
알고리즘 시연 영상
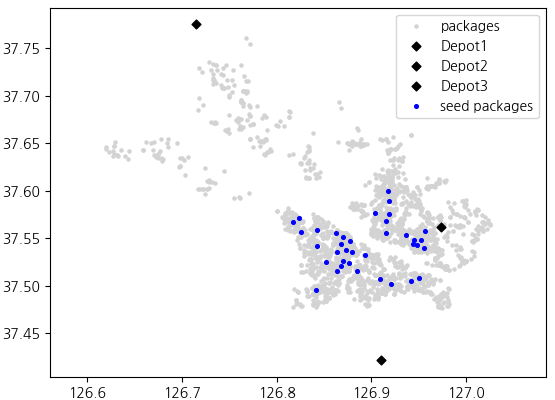
데이터셋: 차고지 3곳, 화물 2205개, 차량 37대 (총 적재가능 부피 = 1805).
결과: 총 1805개 화물을 배달하는 37개 배송경로.
주요 성과
- 2등 수상 (103팀 참가) - CJ 대한통운 미래기술 챌린지 2022.
- 최대 주행가능 거리의 73.5%만을 사용하여 대회 데이터셋의 최대 배송 건수를 달성 (37대 차량, 1,805개 배송지).
- 멀티스레딩을 활용하여 런타임을 20% 단축하면서도 결정론적 결과를 유지.
목적
아래 제약조건을 만족시키면서 최대한 많을 화물을 배달하는 배송경로를 탐색하는 알고리즘을 설계.
차량 제약조건
- 차량별 지정된 차고지에서 시작/종료. 시작 차고지 $ \neq $ 종료 차고지.
- 차량별 정해진 적재가능 부피 (정수로 표시 e.g. 50).
- 차량별 일일 운행 시간 제약 (e.g. 6/20/2022 00:00 ~ 6/20/2022 05:00).
- 일일 최대 운행거리 제약 (110km).
- 차량의 이동속도는 고정 (40km/h).
화물 제약조건
- 화물별 부피 고려 (‘차량별 적재가능 부피’과 마찬가지로 정수로 표시 e.g. 2).
- 화물별 배송지의 하차가능 시간 고려 (e.g. 6/20/2022 01:00 ~ 6/20/2022 02:00). 배송지에 일찍 도착하면 하차가능 시간까지 대기.
- 화물별 하차소요 시간 고려 (e.g. 2분).
- 일부 화물은 배송 차량 고정 (e.g. A00012번 화물은 11번 차량에 의해서만 배송가능).
- 일부 화물은 저상차로만 배송가능. 모든 차량은 탑차 또는 저상차로 분류.
알고리즘 설계
삽입 휴리스틱 (insertion heuristic)과 로컬서치(local search)로 이루어진 휴리스틱 알고리즘을 설계했다.
먼저, 삽입 휴리스틱을 통해 모든 제약조건을 만족시키는 초기 배송경로를 탐색한다. 그 다음, 로컬서치을 통해 경로들을 조금씩 반복적으로 수정하며 개선한다.
삽입 휴리스틱 (Insertion Heuristic)
삽입 휴리스틱은 시드 선택, 시드 삽입, 반복적 삽입 단계로 구성되어 있다.
시드 선택 단계: 각 경로에 처음 삽입되는 화물을 '시드(seed)'라고 한다. 시드 선택 방법은 삽입 휴리스틱의 결과에 큰 영향을 미치므로 중요하다.
Savelsbergh[1]의 방법을 따라, 배송지의 분포 밀도를 기반으로 시드를 선택한다.
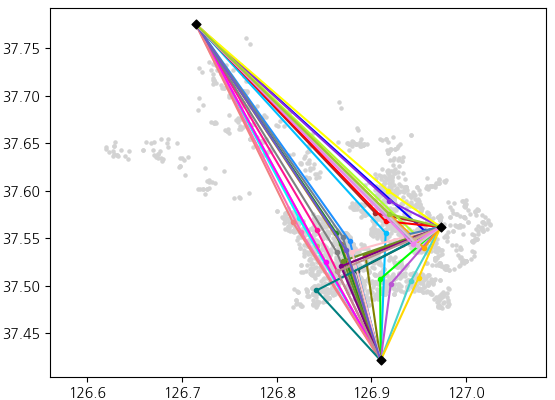
시드 삽입 단계: 선택된 시드는 look-ahead heuristic[1]을 사용하여 각 경로에 삽입한다. Look-ahead heuristic은 비용이 가장 적게 드는 선택지와 두 번째로 적게 드는 선택지 간의 비용 차이를 고려하는 방법을 뜻한다. 두 선택지의 간의 비용차이가 큰 화물을 우선적으로 선택함으로서, 해당 화물이 최적의 경로에 삽입이 불가능해질 경우 발생하는 잠재적 손실을 방지한다.
각 경로에 삽입 비용을 계산하는 함수는 다음과 같이 정의한다. (시작 차고지부터 배송지까지의 거리) + (배송지부터 종료 차고지까지의 거리).
반복적 삽입 단계: 나머지 화물들은 Solomon의 “time-window-based insertion heuristic”[2]을 변형한 알고리즘을 사용하여 경로에 삽입한다. 알고리즘의 변형된 공식은 아래와 같다.
\[c_1 = b_i' - b_i\] \[c_2 = (t_{start} + t_{unload} + t_{end} - c_1 - 2t_{centroid}) \times (p / q)\]각 기호에 대한 설명. (클릭해서 펼치기)
경로 $r$에서 화물 $i$를 배송하기 직전에 새로운 화물 $u$를 추가로 배송해야 한다고 할 때,
- $b_i'$: 화물 $u$를 배송함으로서 늦어진 화물 $i$의 하차 시작시간
- $b_i$: 화물 $i$의 원래 하차 시작시간
- $t_{start}$: 시작 차고지부터 화물 $u$의 배송지까지의 이동시간
- $t_{unload}$: 화물 $u$를 하차하는데 걸리는 시간
- $t_{end}$: 화물 $u$의 배송지부터 종료 차고지까지의 이동시간
- $t_{centroid}$: $r$의 중심점부터 화물 $u$의 배송지까지의 이동시간
- $p$: 화물 $u$의 수익값
- $q$: 화물 $u$의 부피
$c_1$는 새로운 화물을 경로에 추가함으로서 발생하는 시간비용이다.
$c_2$는 해당 화물을 한 차량으로 단독 배송하지 않음으로서 절감하는 시간비용이다.
그러므로, $c_2$가 가장 큰 화물을 우선적으로 경로상 $c_1$이 최소화되는 순서에 삽입한다.
$c_2$ 공식에 추가된 수익값/부피 비율($p/q$)은 알고리즘이 수익 비율이 큰 화물을 우선시하도록 한다.
중심점 기반 패널티($t_{centroid}$)는 Golden[3]에서 영감을 얻었다. 각 경로의 중심점은 새로운 화물이 삽입될 때마다 갱신된다.
경로의 중심점은 경로에 포함된 시작/종료 차고지 및 배송지 좌표의 평균값을 사용한다. 단, 단순 평균이 아니라 차고지 및 화물의 이익/부피 비율에 따른 가중치를 적용한다. 차고지는 데이터셋 내 모든 화물의 평균 이익과 평균 부피를 가진다고 가정한다.
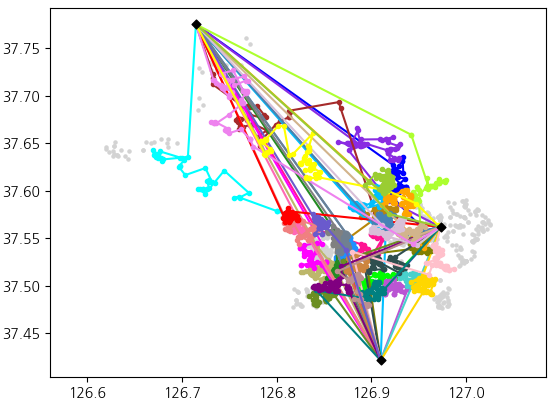
로컬서치(Local Search)
로컬서치는 경로들을 조금씩 반복적으로 수정하며 개선한다.
Aras[4], Mcnabb[5], Vansteenwegen[6]의 연구에서 영감을 받아 로컬서치에 Replacement, Deletion, 1-0 Move, Chain Swap, 1-1 Move, Insertion, Or-Opt 연산자들을 사용했다 (각 연산자의 세부 설명은 Appendix A 참고).
로컬서치는 모든 연산자가 포함된 루프를 반복적으로 수행하고, max_patience 횟수 동안 성능 향상이 없는 경우 루프를 종료한다. max_patience는 하이퍼 파라미터이다.
일부 로컬서치 연산자는 멀티스레딩을 적용하여 속도를 높이면서도 결정론적 성질을 유지하도록 했다 (자세한 내용은 Appendix B 참고).
결과
아래는 알고리즘을 CJ 대한통운 미래기술 챌린지 2022 데이터셋에 실험한 결과이다. 데이터셋은 2205개 화물과 총 1805 부피가 적재가능한 37대 차량이 주어졌다.
- 총 배달된 화물 수: 1748
- 총 시간 비용: 136h 45m 05s
- 총 이동 거리: 3132.8km
- 알고리즘 런타임: 11.0s
- 총 배달된 화물 수: 1805
- 총 시간 비용: 133h 03m 05s
- 총 이동 거리: 2921.3km
- 알고리즘 런타임: 2m 00s
제한점 및 개선방안
- 본 알고리즘의 시간 복잡도는 화물 개수 $n$에 따른 $O(n^3)$이므로, 데이터의 크기가 커질수록 비효율적이다. 그러므로, 이 알고리즘을 대규모 데이터에 적용하기 위해서는 데이터을 독립적인 서브셋으로 분할하고, 각 서브셋에 알고리즘을 개별적으로 적용할 필요가 있다.
- 대회기간 중 시간제약으로 인해 알고리즘을 대회 데이터셋과 대회 데이터셋을 일부 변형한 데이터에서만 테스트했다. 향후에서는 더 광범위한 데이터셋을 활용하여 여러 알고리즘 설계의 성능을 비교/분석할 필요가 있다.
참고문헌
[1] SAVELSBERGH, M. W. P. A parallel insertion heuristic for vehicle routing with side constraints. Statistica Neerlandica, 1990, 44.3: 139-148.
[2] SOLOMON, Marius M. Algorithms for the vehicle routing and scheduling problems with time window constraints. Operations research, 1987, 35.2: 254-265.
[3] GOLDEN, Bruce L.; LEVY, Larry; VOHRA, Rakesh. The orienteering problem. Naval Research Logistics (NRL), 1987, 34.3: 307-318.
[4] ARAS, Necati; AKSEN, Deniz; TEKIN, Mehmet Tuğrul. Selective multi-depot vehicle routing problem with pricing. Transportation Research Part C: Emerging Technologies, 2011, 19.5: 866-884.
[5] MCNABB, Marcus E., et al. Testing local search move operators on the vehicle routing problem with split deliveries and time windows. Computers & Operations Research, 2015, 56: 93-109.
[6] VANSTEENWEGEN, Pieter, et al. A guided local search metaheuristic for the team orienteering problem. European journal of operational research, 2009, 196.1: 118-127.
Appendix A: 로컬서치 연산자
로컬서치는 Replacement, Deletion, 1-0 Move, Chain Swap, 1-1 Move, Insertion, Or-Opt 연산자로 이루어져 있다. Deletion 연산자를 제외한 모든 연산자는 경로의 수익(profit) 또는 효율성을 개선될 경우에만 수행된다.
Replacement: 경로에 포한된 화물을 아직 배차된지 않은 화물과 교체한다.
Deletion: 각 경로에서 최대 3개의 화물을 제거한다 - 수익/부피 비율이 가장 가장 낮은 화물, 거리 비용이 가장 큰 화물, 대기 시간이 가장 긴 화물. 가치가 낮은 화물을 제거하여 경로 간 화물을 이동/교환 할 여유를 확보한다.
1-0 Move: 한 경로에서 화물을 제거하여 다른 경로에 삽입한다.
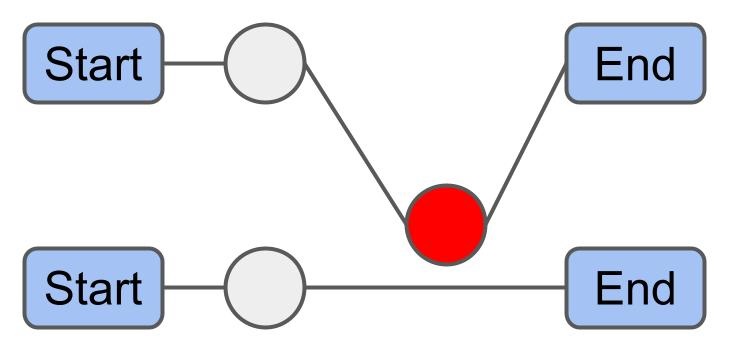
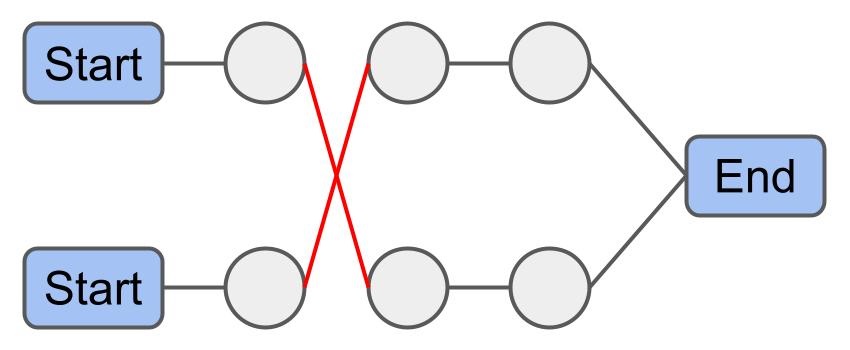
Chain Swap: 경로 $ r_x $와 $ r_y $가 같은 종료 차고지를 가질 때, 경로 $ r_x $의 $i$번째부터 마지막 화물과 경로 $ r_y $의 $j$번째부터 마지막 화물을 교환한다.
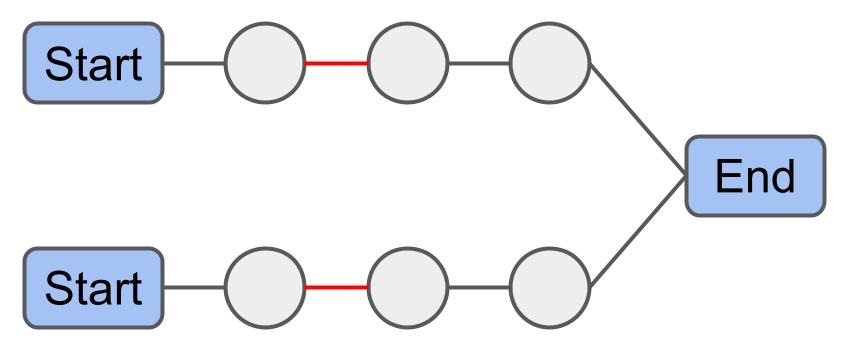
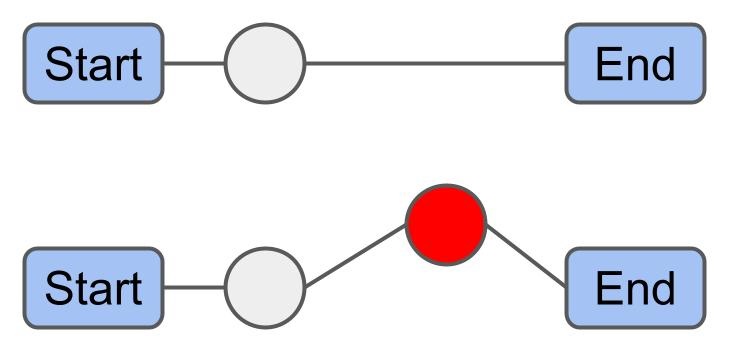
1-1 Move: 경로의 한 화물을 다른 경로의 한 화물과 교환한다.
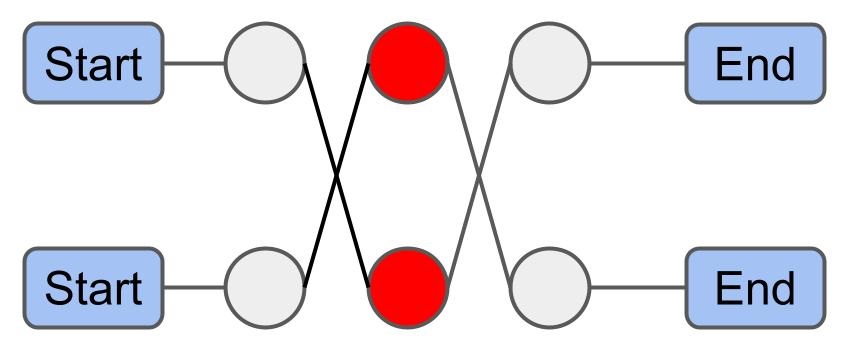
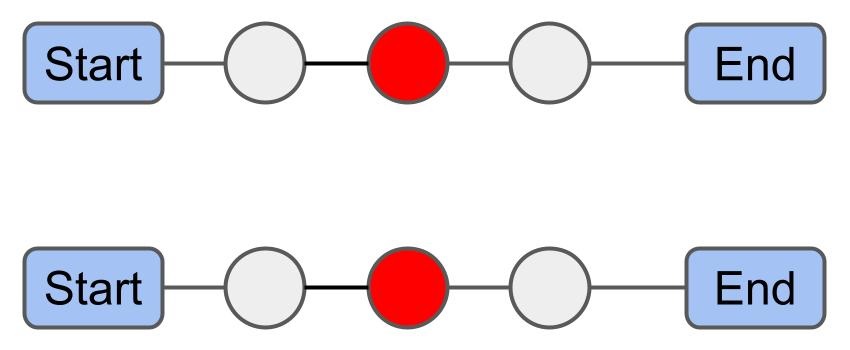
Insertion: 삽입 휴리스틱을 사용해 미배차된 화물들을 경로에 삽입한다. 단, 중심점 기반 패널티는 무시한다.
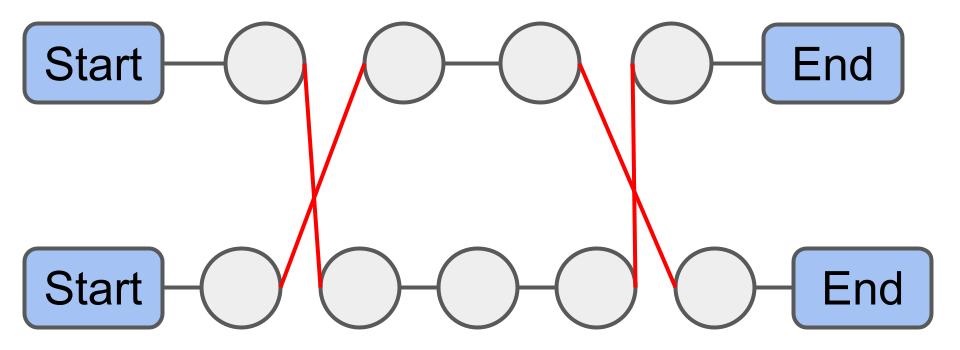
Or-Opt: 경로 $ r_x $의 $i$번째부터 $i+n$번째 화물과 경로 $ r_y $의 $j$번째부터 $j+m$번째 화물을 교환한다.
Appendix B: 멀티스레딩과 결정론적 결과
1-0 Move, Or-Opt 같은 일부 로커서치 연산자는 두 경로간 화물을 서로 교환한다. 이러한 연산자는 모두 아래와 같은 이중 중첩 루프 형식의 구조를 갖고있다.
for (int i = 0; i < routes.size(); ++i) {
for (int j = i+1; j < routes.size(); ++j) {
performLocalSearchOperator(routes[i], routes[j]);
}
}
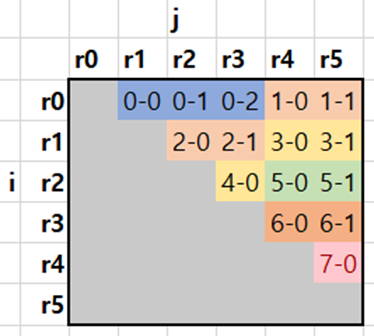
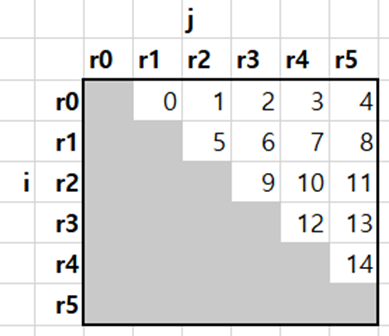
6개의 경로 $r_0$부터 $r_5$까지 주어졌을 때, 위의 코드는 과 같이 나타낼 수 있다. 그림의 각 칸에 적힌 숫자는 싱글스레드 프로그램이 연산을 수행하는 순서를 나타낸다.
을 보면, 각 칸은 왼쪽 칸의 결과에 의존적이란 것을 볼 수 있다. 예를 들어, $r_0$와 $r_3$ 사이에 로컬서치 연산자를 수행한 2번 칸의 결과는 $r_0$와 $r_2$ 사이에 로컬서치 연산자를 수행한 1번 칸의 결과에 따라 바뀐다 (두 칸 모두 같은 $r_0$를 공유하기 때문).
이와 비슷하게, 각 칸은 위쪽 칸의 결과에 의존적이다. 예를 들어, $r_2$와 $r_4$ 사이에 로컬서치 연산자를 수행한 10번 칸의 결과는 $r_1$과 $r_4$ 사이에 로컬서치 연산자를 수행한 7번 칸의 결과에 따라 바뀐다 (두 칸 모두 같은 $r_4$를 공유하기 때문).
결정론적 결과를 유지하려면, 멀티스레드 연산 순서가 앞서 설명한 싱글스레드의 연산 순서와 동일한 의존성을 유지해야 한다.
은 의존성을 유지하면서도 멀티스레드로 작업을 분할하는 방법을 보여준다. 그림의 각 칸에 표시된 숫자는 (스레드 ID) - (스레드 내 실행 순서)를 나타낸다. 같은 색의 스레드는 동시에 실행되며, 각 스레드는 왼쪽과 위쪽 스레드가 모두 실행을 완료한 후에 시작된다.
따라서, 마치 어셈블리 파이프라인과 유사하게 0번 스레드가 실행을 완료하면, 1번화 2번 스레드가 동시에 실행된다. 그 다음, 1번과 2번 스레드가 완료되면, 3번과 4번 스레드가 동시에 실행된다.
이와 같은 멀티스레딩 패턴은 싱글스레드와 같은 결과를 유지하면서도 효율적으로 작업을 분할한다.